{kind=link}
本コーナーではメールで寄せられた質問に可能な限りお答えします。 ただし、メールで直接答えた方がいい場合や、 明らかに単純なこちらのミスで正誤表で対応した方がいい場合はそのようにします。 また、必ずしもお答えを約束することもできませんのでご了承ください。
また、質問ではなくこちらの知らないことをご教示いただいた場合で、 本書の内容を越えるなどの理由で正誤表で対応しないものも、以下に掲載します。 ご教示くださった方には、この場を借りてお礼申し上げます。
p.600 で作ったコマンドラインプロンプトへのショートカットは、 デフォルトのフォルダとして C:\WINDOWS を指定していますが、 このフォルダで何か作業をするのは不穏当ではないでしょうか。
また、本書は p.56 をはじめ C:\ を作業フォルダに使っていますが、 ここも作業フォルダとしては不適当ではないでしょうか。
コマンドラインプロンプトを起動した直後のフォルダを設定する方法を説明した方がいいと思います。
普段は FreeBSD をお使いの方のご意見で、 ヘンなフォルダ(UNIX 用語ではディレクトリ)で作業したくないし、 初心者の方にもして欲しくない、という話です。
実際には各ユーザーの作業フォルダである C:\Document and Settings\ユーザー名\ あたりが適切かもしれません。 フォルダ名にスペースが入っているのでスクリプトで使うときちょっとやっかいな時もあるが)
コマンドプロンプトに限らず、あるプログラムのショートカットを作成したあとに、 起動直後の作業フォルダを指定することができます。 これには以下の手順を取ります。
これで、次回から cmd.exe を起動したときに、 C:\Document and Settings\ユーザー名\ が表示されます。
windir は Windows のシステムファイルが入っているフォルダが、 homepath はログイン中のユーザーの作業フォルダが格納されている環境変数です。 コマンドプロンプトで set(改行) と入力すると一覧表示されます。
p.600 の NOTE で Windows NT 系はコマンドのヒストリーを↑↓でたどったり、 ←→で編集したりできるので便利、と書かれていますが、 Windows 9x でも doskey というコマンドを使うと同じことが行えます。
ご指摘ありがとうございます。ぼくはもう 9x 系は捨てているので…。
http://forum.nifty.com/fpcu/dosvcmd/doskey.htm などが参考になりますね。autoexec.bat を編集すれば常駐もできるでしょうね。
p.254 などで 0x0d0a という記述をされていますが、これは 0x0d0x0a と書くべきではないでしょうか。
たしかに 0x0d0a と書くと、4 桁の 16 進数(10 進変換すると 3338)という意味に取れ、
$num = 0x0d0a;# $num には 3338 が入る
のような Perl のスクリプトを書いてもそのように動作するようですが、 Windows の改行コード CRLR の 2 バイト 0x0d+0x0a を示す言葉として RFC でも使われているようです。 想像ですが、口頭で "hexadecimal zero-a zero-d" とか言ってたのを写したものではないでしょうか。
p.69 で RFC は ASCII で書くから原則英語、と書かれていますが、ラテン語などの他の言語も ASCII だけで書けます。 用字(スクリプト)と言語(ランゲージ)を区別した方がいいと思います。
おっしゃるとおりで、ぼくも同じことを書いています(p.322 メモ参照)。 が、現実問題 RFC は原則英語で書かれているようです。
p.103 にそのようなことが書かれていましたが、よくわかりませんでした。
コンピューターを操作するために「ミサイル発射」とか「残高照会」とか マイクに言う状況を想像して書きました。 さいきんの家電サポート電話窓口などは「掃除機」というと掃除機の係の方が出てきたりしますね。
p.105 図4.7 では「ボレット」となっていますが、手元の辞書では[b#'ulit]となっています。
これ、外人と話すと「ボレット」に聞こえるんですよねー。 goo の辞書では「ブーレット」に聞こえますね。 (ちなみに「スティーブ・マックイーンのブリット」という映画もあったな)
こんなの何が正しいかという問題ではないので、多数決で決めます。Google で聞いてみると…。
うーんボレットは圧倒的少数派ですね〜。みなさんブレットを使ってください ;;;
p.106 図4.8 で「なぜイタリックだと斜体なんでしょうか」と書いてありますが、 草書体から来ていると思われます。 イタリック体活字を創作したのは、Aldus Manutius(ca.1452-1515)だそうです。
Aldusの略歴と業績については
そのイタリック体活字については、
最後のページには彼のイタリック体の図版も載っていて、
Italic type is a version of Roman. It was based on the cursive but highly legible hand called Cancelleresca used in the government offices of Venice and other Italian city-states. Aldus was the first to adopt Italic as a printing font and it was an unqualified success. The models for the Aldine Italic fonts were probably the hands of two scribes Pomponio Leto (1428-1497) and Bartolomeo Sanvito (b. 1435).
だそうです。
なお、「イタリック体」と「斜体」とは区別するのが正しいそうです。
へ〜(×10)。勉強になりました。
p.125 に、加藤弘一氏の「図解雑学 文字コード」の見解として、 「よくリガチャー(合字)の例として fi のような字があげられるが、 実際には ß(<=ss)のような元の字形を残していないものを呼ぶ」と 書かれていますが、OE や AE のリガチャーも元の字を残しています。
また、西島九州男監修「校正技術」(日本エディタースクール出版部,1973年)によると 合字(ligature)とは、
2字以上の活字を1本の活字に鋳込んだもので、字づらには共有部分が認められる。(p.534)
と書かれていますが、この「共有部分が認められる」ということの方が重要ではないでしょうか。
また、ß は ss の合字ではなく、 歴史的には ß という字が先にあって、 それを後世で ss と書き換えたようです。 もし ß が合字だったとしても sz(エスとツェット)の合字ではないでしょうか。 ドイツ語のオーラ
前掲「校正技術」でも ß は合字の例には入っていません。
また、ß は ドイツ語の古い活字では長いエス(深沢注:積分記号のインテグラル∫のようなもの? とか書いてまた問題を複雑にする…;;)とツェットの字形を残しているようです。
http://www.lg.fukuoka-u.ac.jp/~ynagata/gif/cpe_test.gif の下から2行目、
... Es ist gewiß zu glauben, ...
をご覧ください。
よって、「文字コード「超」研究」のp.125 のメモだけでなく p.124 の本文の中にも
「…fi のように f と i がくっつく場合もリガチャーと呼んでいます」などと、文字が元の形を変えたままくっつくことを傍流のように書かれているのは、 少なくとも昔の印刷職人さんには疑問を抱かせるものではないでしょうか。
ご教示ありがとうございます。 まず fi のように元の字の原型を残しているものが 傍流であるという認識はわたしにはありませんでした。 本文からそのようなニュアンスが伝わったとすれば筆力のなさに伴う誤解です。
で、fi のことをリガチャーと呼ぶのが正当であるかないか、 エスツェットをリガチャーと呼ぶのが正当であるかないかは、 すいません、わたしにはよくわかりません。;;; (OE のリガチャー Œ がリガチャーであることに見解の相違はないようです。)
ただ、いろいろな見解がある場合は作業の現場でもいろいろな見解があるということで、 どの人がどういう意味で言葉を使うか事前に察知できませんから、 いろんな見解を並列で紹介するという方針を取っています。
とまれ、
というのは大きなポイントですね。どうもありがとうございました。 あと、世間の趨勢は圧倒的に fi をリガチャーと呼ぶことにしているようですね。
原メールはもっと内容があったのですが割愛させていただきました。 TM さんにはリガチャーと TeX の処理についても面白いご教示をいただきました。 なんでもリガチャーを含む TeX ファイルを ps2ascii でテキストファイルに戻すと 2 字に分離するそうです。
これは本文 p.29 の記述に反して UNIX 改行になっているのではないでしょうか?
申し訳ありません。おっしゃるとおりになっていました。 これは Web サーバーが UNIX を使ってい、FTP のアスキーモードで送信したために起こった現象です。 これは本書でも p.256 で説明しています。(なのに自分でハマっているという…;;;)
8/3 以降は zip 形式で圧縮したファイルに差し替えました。 これでバイナリーモードでアップロードされますので、改行コードの変換はおきません。
まず、Windows におけるファイルと既定のアプリケーション (ダブルクリックすると起動するアプリケーション) の関係は、拡張子(ファイル名の最後のピリオド以降。a.txt の場合 txt)で決まります。
txt ファイルの既定のアプリケーションは、Windows エクスプローラで [ツール] => [フォルダ オプション] => [ファイルの種類] で TXT をクリック選択して見ればわかります。 ここで [変更] をクリックすれば [メモ帳] を選択することも、 [xyzzy] を選択することも、他にたとえば Microsoft Word を選択することもできます。
ところで、メモ帳は Windows 9x/Me のものと Windows XP のもので挙動が異なり、 前者は 64KB 以上のファイルを読み込むとワードパッドが起動して変わりに読み込むように なっているそうです。ぼくは XP なので気づきませんでした。ありがとうございます。
p.551 下部 NOTE に
「<font> コマンドは HTML 4.0 の規格ですでに廃要素になっているので、 公式には使えません。」と描かれていますが、現在でも使えます。 HTML4(現在は4.01)は 3 つの文書型定義を持っており、 それぞれ Strict DTD / Transitional DTD / Frameset DTD と呼ばれています。 このうち、Strict DTD においては、確かにfont 要素型 は削除されています。 Strict DTD に従って書かれた文書においては、font 要素は出現してはいけません。しかし残りの 2 者においては font 要素型は残存しています。 Transitional / Frameset DTD に従う文書においては、 font 要素を堂々と「公式に」使用することができます。 アクセシビリティの観点から、使用が望ましくないのは確かですが…。
これは、現在HTMLの仕様として最新のものであるXHTML1.0においても同様です。
そもそも、HTML4.0 /4.01 が出たからといって、古い HTML3.2 の仕様が 廃止されたわけではありません。現在でも HTML3.2 準拠の文書を 作ることはできますし、その場合は当然ながら font 要素型を使うことができます。
ありがとうございます。勉強しましたが、ご指摘の通りですね。
ここでアクセシビリティについて読者の方にぼくが理解したことを述べますが、 色々な種類のブラウザーをお使いの方や弱視の方など、 なるべく数多くの人が作成者の意図どおりに Web ページをアクセスできることを目指し、 特に音声読み上げ Web ブラウザーやマウスを使わないキーボードブラウザーを サポートすることも視野に入れて Web デザインを行うことで、 HTML 4.0 の Strict 文書型定義はこの主義に厳密に(strict)従っていますが、 一方 Transitional(移行期の)と、そのフレーム対応版の亜流である Frameset は 過去とも互換性を保っているという状況だそうです。
本書執筆時は HTML 4.0 で完全に font 要素型が廃止されたと誤解していて、 同じような記述が数箇所にありますが、正誤表でも対応します。
第2刷でこの記述は変更しました。
p.122 最下部のメモを以下のように改稿しました。
HTMLの <font> タグはHTML 4.0規格のStrict文書型定義では削除されました。 このような物理的な指定はブラウザーに依存するので望ましくないという意見もありますが、 過去のHTMLとの互換性のために残っています。
p.551 下の NOTE の記述を以下のように改稿しました。
<font>要素はHTML 4.0のStrict文書型定義では削除されており、 フォントの指定はCSS(Cascading Style Sheetいわゆるスタイルシート)で 行うことになっています。過去との互換性から削除はされていませんが、 このようないわゆる物理タグはアクセシビリティ (目が不自由な方のための読み上げブラウザーや携帯端末を使う人でも HTMLから情報を読み取れるようにすること)の観点から排除していくべきだという 意見もあります。 また、「MS明朝」は「MS Mincho」のようにローマ字でも指定できるようになっています。 この名前はフォントファイル名によるものです。 MS明朝の場合は同じフォントが日本語と英語の2つの名前のファイルに入っています。
ご指摘いただいた TH さんに改めて御礼を申し上げます。
p.581「<meta> タグによる charset 指定」に、
と書かれていますが、文字セットは HTTP ヘッダーによっても伝えることができます。
META 要素による charset の指定は、HTTP ヘッダーで与えられなかった情報を補完するために 書くことができる、という意味です。http-equiv という属性名にもそれが現れています。 (深沢注:equivalent は「〜に相当する」という意味) HTTP ヘッダーで文字セットが伝えられていれば、ブラウザーは文字セットを知ることができます。
おっしゃる通りです。本書は HTML の内容は「従」ですので、内容は割愛しましたが、 割愛の仕方がちょっと誤解をまねく表現だったようです。
HTTP ヘッダーとは、ブラウザーが Web サーバーに Web コンテンツの取得要求をしたときに、 コンテンツ(この話題の場合は HTML ファイル)の先頭に、その文書の属性をくっつけて寄越すものです。
HTTP ヘッダーの指定方法はおおまかに 2 つあります。
Apache の場合は設定ファイル httpd.conf に Addlanguage 指示子などで指定します。たとえば
AddCharset EUC-JP .html
という行を httpd.conf に指定すると、拡張子 html のファイルはすべて EUC-JP であるとブラウザーは知ることができます。
CGI スクリプトは標準出力に Web スクリプトの内容を記述します。 このとき、出力する HTML の内容に先立って HTTP サーバーを出力します。 (CGI はサーバーサイドで動作し、ブラウザーに到着するときは HTML になります。) Perl で CGI スクリプトを書くとすると、以下のような記述になります。
print "Content-type: text/html;charset=Shift_JIS\n\n";
print "<HTML>こんにちは</HTML>";
これで次のような内容の HTML が送信されます。
<HTML>こんにちは</HTML>
と同時に、ブラウザーには文字セットが Shift_JIS であるという情報が通知されます。
なお、CGI プログラムを Web サーバーに設置するときには、 ディレクトリ、拡張子、ファイルの権限などに制限があります。 また、レンタルサーバーの場合は CGI 禁止の場合もあります。 詳しくはお使いの Web サーバーの管理者にお問い合わせください。 また、拙著すぐわかるPerlにもかすかに CGI について書かれています。(とかいって宣伝しとるわ。ぬはは)
HTTP ヘッダーが正しく charset を使えていれば、 META タグがなくてもブラウザーは文字コードを知ることができます。 原文の本意は、HTML ファイルはテキストファイルなので、 それ自身が単独で文字セットを伝えるには META タグを使ってくださいという意味でした。
第2刷でこの記述は変更しました。
p.581 見出し「<meta>タグによるcharset指定」の直下の記述を以下のように変更しました。
第 1 刷:Webページがどのエンコーディングスキームになっているかは、 クライアント側では事前に知るよしもありません。
第 2 刷:HTMLファイルはプレーンテキストですので、 どのエンコーディングスキームになっているかファイル自身ではわかりません。
また、p.582 COLUMN の上に以下のメモを挿入しました。
HTMLファイルのエンコーディングスキームは Webサーバーの設定などで付加されるHTTPヘッダーによっても渡されます。 <meta> タグはHTTPヘッダーの設定を上書きできるわけです。
p.583「22.4 XML」に「(XML は)カンタンに言うとタグを勝手に定義できるのが特徴です。 (中略)タグの定義は別に DTD(Document Type Definition)というもので行います。」と書かれていますが、 XML に DTD は必須ではありません。
DTD を有しそれに適合した文書は「妥当(Valid)」な XML 文書と呼ばれますが、 DTD がなくとも XML の一般的なルールに従っていれば「整形 (Well-Formed)」な XML 文書となります。 本格的な業務に用いるため厳密にDTDを設計するような場合はむしろ稀で、 一般的には整形式XMLを使用することが多いと思います。 また、DTD は要素型・属性間の関係を定義するためのものであって、 どのように表示させるかは HTML 同様スタイルシートに依存します。
また、XML文書とエンコーディングの関係が本文記述からほとんど欠落していますね。 Character Encoding in Entities が参考になります。
ありがとうございます。 これも XML の記述をあくまでオマケ的に付けたためにおきた現象です。 (言い訳めきますが、本書はもう限界に近いほど分厚くなっていて、 泣く泣く割愛した部分もあります。) 原文の本意としては、DTD を使えば XML で論理的な関係を示すタグを定義できる、という意味です。
第2刷でこの記述は変更しました。
p.583 一番下の段落を以下のように変更しました。
第1刷:このように書いて、タグの定義は別にDTD(Document Type Definition)と いうもので行います。こうして、文書内では論理的な内容(セマンティクス)だけを記述し、 どのように表示させるか(シンタックス)はDTDに分離して書くというスタイルです。
第2刷:このように書いて、独自タグの定義は別にDTD(Document Type Definition)というもので 行うことができます。こうすれば、文書内では意味内容(セマンティクス)だけを記述し、 個々の文字列がどのような論理構造を持っているか(シンタックス)はDTDに分離して書くことが可能になります。
p.491 に「Unicode では「平」の「ソ」と「ハ」の違いを包摂(Han Unification)しているが、 アジア人であればこれは字体の違いだから、包摂せず、別のコードポイントを与えているだろう、 という趣旨のことが書かれています。
しかし、JIS 基準では字体の異なる字も包摂しています。 事実、JIS X 0213:2000 規格票の 6.6.3 では「漢字の字体の包摂基準」となっています。
また、JIS では「平」の「ソ」と「ハ」の違い(SimSun フォントの平)と(MingLiu フォントの平)の違いも包摂しています。 JIS X 0213:2000 規格票 6.6.3.2「漢字の字体の包摂基準の詳細」表 3 の連番 13 に載っています。
また、右骨と左骨(SimSun フォントの骨)と(MingLiu フォントの骨)の違いですが、 これが JIS で包摂されていないのは別の字として使い分けが活発に行われているからではなく、 JIS で調査した範囲では現代における左骨の用例がなかったため包摂されていないだけだと思います。 (昭和初期の用例ならあるそうです。) もし左骨の現代用例があれば、逆に包摂されていたと思います。 これは、わたし(深沢注:NH さん)の想像ではなく、 JCS 委員長芝野耕司氏が同じ意味のことを言っているのを聞いたことがありますし、 JIS の包摂基準をじっくり眺めれば誰でも類推できると思います。
ご教示ありがとうございます。
まず、包摂基準が字体にも及ぶことを自分としては認識していました。 原文の本意としては、アジア人当事者としては違う字であっても Han Unification では包摂されてしまっている字があるのではないかということを、 できれば例つきで示したいというものでしたが、誤解を招く文章でした。
次に、「平」の「ソ」と「ハ」の違いについては、 完全に油断していて包摂基準が明文化されていることを見落としていました。 (つまり、骨と同じ状態だと思っていました。) また、「骨」の左右が包摂されていないのは一方を使っていないから、 という考察は目からウロコですが、確かにそのようですね。これは勉強不足でした。 ということで、本書の筆者は JIS 規格の読み込みが足りませんね。 今後もご教示願えれば幸甚です。
第2刷でこの記述は変更しました。
p.491 冒頭より
第1刷:この違いは、当事者のアジア人にとってはもはや字体の違い、 つまり、もしJISがこれらの字を管理していれば、包摂せずに異なるコードポイントを 与えても仕方ない字とみなされてしかるべきでしょう。
第2刷:これらの字の形の違いは当事者のアジア人にとっては明らかですが、 それ以外の国の人には見分けがつかない場合が多く、 これが同じコードポイントを与えられているためにコンピューター部品の箱などで 散見されるヘンな漢字の原因になります。
このように、
ということで、JIS との(架空の)対比において Han Unification の問題点を書くのをやめました。
原文の本意は、Unicode の世の中になって日本語スクリプトの中に 同じコードポイントに割り当てられている中国漢字が表示されることがありうるので 注意しましょう、というごく常識的な問題です。
p.491 のコラムで柔道の篠原選手の件が扱われていますが、 朝日新聞の記事も、JIS X 0213 の例示字体も、記憶によれば柔道着のゼッケンも 「竹/夂/木」になっていましたが、 本書ではすべて「竹/夂/ホ」になっています。 後者は中国(大陸)出自の U+7B7F 例示字体と同じです。 わたしは漢字統合批判派ではありませんので 「中国のシノを使うなどけしからん」とは決して言いませんけど。 また、同コラム中にシノは JIS X 0213 で 2-13-41 に収録されたという 記述がありますが、2-83-41 だと思います。
新聞記事と JIS 規格票例示字体は確認しました。たしかに
ケケ 条
ですね。(ゼッケンは確認できませんでしたし「記憶」もありません ;;;) これ、作字を頼まず U+7B7F を単純に指定していました。 ご指摘ありがとうございます。 また、コードポイントの件もありがとうございます。 こちらは正誤表でも対応しました。
第2刷でこの記述は変更しました。
p.492 の柔道のシノ原のコラムの末尾に下のメモを入れました。
メモ:本書第1刷の読者の方から「朝日新聞はUnicodeを使っていない。 また、新聞紙面のシノの字のアシは『木』で、Unicode例示字形のアシは『ホ』であり、 後者は中国由来のものである」という趣旨のご教示をいただきました。
NH さんに改めて御礼を申し上げます。
ありがとうございます。 この Web はこっそり直しました。(もうこっそりにならないが)
書籍上も間違ってますね。正誤表で対応します。申し訳ありません。
2003/07/31 TM さんからのお便りでは、 エスツェット(ß)は歴史的に long-s と z のリガチャーだという説を採られていますが、 他に、long-s と round-s(short-s)のリガチャーだという説もあります。
後者の説はヤン・チヒョルト『書物と活字』に見られるもので、 同書では z 説は俗説として切り捨てられているようですが、 Web を検索した限りでは z 説の方がむしろ優勢なようです。
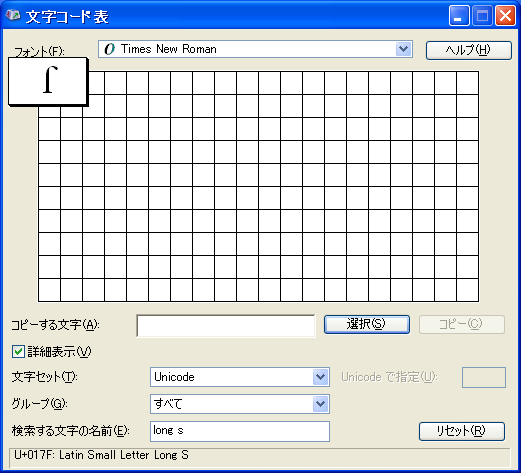
ちなみに long-s は U+017F で符号化されています。 f のクロスバーを抜いたような字で、この字をイタリックにすると積分記号のようになります。
ありがとうございます。ついにおたよりコーナーの中でやりとりが始まってしまいましたね。(^^)
本書 p.47 で紹介している Unicode 文字名で検索する手法で 「long s」を検索すると U+017F が見つかりました。
この字=>「ſ」ですね。
エスツェットの由来がヨーロッパでも諸説あるというのは面白いですね。 (ヤン・チヒョルトはスラブ系のドイツ人)
まず、リガチャーは「合字」の意味で使われる限り、印刷用語です。 さらに言えば、もともと欧文タイポグラフィ(深沢注:活版印刷および組版デザインのこと)の 用語です。
もちろん、活版印刷以前の時代にも ae の結合形などはありましたが、 それを「リガチャー」と呼んでいたかはわかりませんし、 そもそも 15 世紀以前(!)に「リガチャー」という言葉がどのような意味で用いられていたかなど気にする必要もないと思います。
ジェイムズ・クレイグ著『欧文組版入門』では、リガチャーは以下のように定義されています。
Ligature(リガチュア):合字のこと。
手組み用の金属活字や鋳植機の活字で、ひとつのボディ、あるいは字母に、 ff, ffi, ffl, Ta, Wa, Ya などのように、 2 文字か 3 文字をまとめたもの。
ただし、ひとつのボディに鋳造されたロゴタイプの文字列は 合字とは別である。
(深沢注:ロゴタイプとは社名や商標のような場合に複数の字を 1 つの活字に鋳造したもの)
TM さんの引用されている『校正技術』の定義とほぼ同じですが、 『欧文組版入門』のほうは「共有部分」の有無を条件としていません。 また、挙げられている例も ff のクロスバーが連続している以外には共有部分を持ちません。
(深沢注:ここでいう共有部分とは、fi がくっついて i の点が消えるとか、 ff がくっついて境目が消えるといったことです)
金属活字を用いない現代の組版に適用しやすいのは 「字づらには共有部分が認められる」とする『校正技術』の定義のほうでしょうけれど、 あくまでもリガチャーの本質は、ふたつの定義に共通して見られる 「ひとつのボディに複数の文字をまとめたもの」 であるという点は押さえておきたいと思います。
そのようなわけで、複数の文字がひとつのかたまりとしてデザインされ、 (なおかつ)共有部分を持つ U+FB01(fi リガチャー)は明らかに典型的なリガチャーでしょう。
(深沢注:「fi」という Unicode です。)
一方、エスツェットがリガチャーかというと、違うと思います。 「複数の文字」という条件を満たしていないからです。
もちろん、エスツェットは歴史的にはリガチャーから形成されたものでしょう。 Unicode 3.0 にも、“in origin a ligature of 017F and 0073”とあります。 (round-s 説ですね。 )
しかし、たとえばアンパサンド(深沢注:&)は 歴史的には et の結合したものですが、 現代の通常の文脈では、 「アンパサンドはリガチャーである」とは言わないと思います。
(深沢注:Unicode 規格書でのエスツェットの定義を訳すと 「もともとは ſ と s のリガチャーだった」となります。
ちなみに round-s = U+0073 は Latin Small Letter S つまり ASCII の s のことです。 この定義はUnicode.org の Code Chartで 見ることができます。)
欧文のリガチャーは、2 種類に分類することができるように思います。
- タイポグラティ的な観点から複数の文字をまとめてデザインしたもの。
- 何らかの目的で複数の文字をくっつけて 1 つの文字として扱うもの。
fi リガチャーは前者、 ae リガチャーは後者(古英語の発音をラテン文字で表記するために生まれた) に分類できると思います。
エスツェットについては、もともと前者であったものが、固定化して「文字」になった例ではないでしょうか。
(深沢注:ae リガチャーは U+00E6(æ)および U+00C6(Æ))
ありがとうございます。(こんなに勉強させていただいていいんでしょうか・・)
ポイントは、
ということですね。
エスツェットがもはや 1 字、というのは、 先のお便りのエスツェットの由来がヨーロッパでも諸説分かれている、 ということからもうなづけますね。
第 2 刷でこの記述は変更しました。
上の方でTMさんが議論を提起されたこの問題ですが、 第1刷には加藤弘一氏『電脳社会の日本語』からの見解として、 「fiリガチャーは真の意味でのリガチャーと言えず、 エスツェットのような個々の字の原型を留めていないのが真のリガチャーである、 という話もある」 という話をメモとして紹介しましたが、上記のようななりゆきで、
という NH さんの見解に納得しましたので、メモは削除させていただきました。
パターン認識能力があれば女の子に見えるはずだ、と書かれているので猛烈に不安です。
これ、当初から言われていたんですが、おたよりがついに 3 通に渡ったので触れます。 この絵は全体の装画を担当してくださった長谷川さんのものではなく ぼくが自分で書きました。モデルもいる少女像なんですが、そうですか、見えませんか・・・。
「Gates.l(第1刷では間違って Gates.el)を設定ファイルにロードすれば、 と書いてありますが、直前に ISO8859-1 の設定の仕方について書かれているように 「(require "gates") と .xyzzy に書く」と書いた方がわかりやすいのでは。
xyzzy の設定についても、Perl についてと同じくどこまで書くか悩みました。
本書は本題である文字コード系の原理についてと同じぐらい、 それを現実の業務でどうハンドリングするかも書いてるのがミソなんですが、 あんまり調子に乗って書いていると別の本になってしまうので考えどころです。
.xyzzy に Lisp コマンド require を書くことと、 その本体が外部のファイル Gates.l を読み込むことが同じであることを、 なんとなく書くつもりだったんですが、もう少し工夫します。
JIS X 0201ですでに(いわゆる半角)カタカナは使えるわけなんですが、 そっちの立場はどうなるでしょうね。
なるほどー、一本取られましたね。
まず、本ページの上の方でも書きましたが、 文字コード系と言語(スクリプト)は関係ありません。 ASCII もローマ字表記を考えれば、日本語が書けない掛けないわけではありません。
一方、カタカナだけで日本語を書いても、そこはおのずと制限があります。
「ワタシノナマエハイヴ・・・!コンピューターデス・・・!」
などと大昔の SF のようなカタカナ表記で日本語を書いたとしても、 「分かち書き」をしなければならないといった点で、通常の日本語表記とは 大きく異なります。
JIS X 0201 は、 ASCII に加えて西ヨーロッパ特殊文字を使えるようにした ISO 8859-1 と同様、 ASCII の右半面に(いわゆる半角)カタカナを押し込んだもので、 アジア系言語を、ちょっと雰囲気的な書き方になりますが「本格的に」 使うために多バイトの概念を持ち込んだ JIS X 0208 とは、 やはりインパクトが違います。
そうした意味で「世界初の多バイト文字コードであり、世界初のアジア系文字コード」 という書き方をしたのですが、どうしたもんでしょうね。
第2刷でこの記述は変更しました。
第1刷:世界で最初のアジア文字コードであり、
第2刷:世界で最初の国際的、本格的なアジア文字コードであり、
のように形容詞を入れて曖昧にしました ;;;
わたしの本意は上述のようです。
また、NAさんは「CTSの内部コードとしての日本語コードは JIS X 0208 以前にも あったのではないか」というお便りを後にいただきましたが、 これももっともなご意見と存じます。「国際的、本格的な」でごまかされてください ;;;
p.503 の上の方のメモに「たとえばrightという英単語は2音節、leftという英単語は 2音節になります。」と書かれていますが・・・。
その通りです ;;;
right(goo の辞書)の [ai] は二重母音と言われ、これも1音節に数えます。一応知ってはいたんですが(というか学校で習いますが)完全に油断しました。
本書 p.325 で書かれているハイフネーションの話題にも関連しますが、 音節(syllable)の区切れは辞書ではハイフンが入っています。 行末でのハイフネーションはシラブルの区切りで可能になる、ということになります。 left 同様 right も辞書上でハイフンが入っていず、1シラブルであると分かります。 この [ai] のような音を二重母音といいます。
また doom の [u:] のような音を長母音といいますが、これも 1 シラブルに数えます。
第2刷でこの記述は変更しました。
「たとえばhappyという英単語は2音節、sadという英単語は1音節になります。」
としました。
happy という単語を goo の辞書で引くと hap-py となっていて、2音節と分かります。
(と、間違えたことを書いた身分で長々と講釈を垂れる俺! ずうずうしい俺! ;;;
503ページに
ハングルの字母は 51 種類ぐらいですが、これを組み合わせると 論理的には 10,733 種類となります。
とありますが、この 51 種類というのは、Unicodeの「ハングル互換字母」ブロック内の文字から、 古語ハングルを除いた総数だと思います。
(深沢注: Unicode.org の資料としては http://www.unicode.org/charts/PDF/U3130.pdfに載っています。)
現代の字母は Modern lettes で 0x3131〜0x3163 の 51 種類です。 「古語ハングル」は Archaic letters として載っています。
しかし、ハングルは
初声(子音)×中声(母音)×終声(子音)
の組み合わせで出来ています。
503ページ〜504ページで例として挙げてある U+AC10 の場合、 初声がKiyeok (kもしくはgの音) / 中声がA (aの音) / 終声がMieum (mの音) となります。
(ちなみに、「ハングル字母」ブロックでは、同じ子音でも初声と終声と別々に 符号化されています。)
(深沢注: U+AC10 は Unicode.org の http://www.unicode.org/cgi-bin/GetUnihanData.pl?codepoint=ac10 に載っています。このように、Unihan の han は漢字の漢ですが、 漢字だけでなく完成形ハングルも Unihan Database に載っています。)
で、
初声 19 個 * 中声 21 個 * (終声 27 個 + 終声無し 1 個) = 11172 個
が、論理的に可能な現代ハングルの個数で、 これらが「ハングル音節」ブロックの全ての文字です。
0xac00 + (初声番号 * 21 * 28) + (中声番号 * 28) + (終声番号)
で Unicode 番号が計算できます。
(注意:初声19個とか中声21個というのは、Unicodeでの解釈であって、 言語学的にはいろんな分類方法があるそうです。)
また、Unicode のハングル音節ブロックが
AC00;<Hangul Syllable, First>
D7A3;<Hangul Syllable, Last>なので、この数も 11172 個となります。
よって、本文の 10,733 個ではなく 11,172 個が正しいのではないでしょうか。
また、p.503 の中へんに Johab(チョハブ:組み合わせという意味)と書かれていますが、 チョハブは組合という漢字のハングル読みそのものです。
ご教示ありがとうございます。 (NA さんもお便りの他の部分で斟酌くださっているように)日本語中心の本なので ハングルにあまり深入りできず、ぼくも深く勉強できていません。 字母 51 種類/組合形 10733 個というのは参考文献から引き写したものです。
たぶん NA さんもおっしゃる「言語学的な数え方の 1 可能性」なんでしょうが、 Unicode との兼ね合いにおいて書く以上、11172個が正しいですね。 チョハブの件と合わせ、正誤表で対応しました。
ハングルは非常に面白く、また日本人にとって研究する必要が高い文字ですね。 今後もご教示賜れれば幸甚です。
p.139 に「C や Perl ではべき乗の計算に ** を使う」と書かれていますが、 C では pow() 関数を使い、** は使えないと思います。
すみません・・・。
pow() は math.h に入っている関数で、power(べき乗)の略ですよね。
math.h をインクルードするには cc に -lm(library of mathematics?)スイッチを 渡すんですよね。
ちなみに C では ** はポインタのポインタの解決に使うんですね。
とかいろいろ言っても失敗の糊塗にはなりませんね ;;; ありがとうございます。